⭐订单超时自动取消如何实现?
如果在用户在一定的时间(比如 24 小时)内没有付款,那么订单会自动被取消,这是电商和外卖平台很常见的一个功能。当你的简历中包含商城、外卖类型项目的话,问到这个问题的概率还是比较大的。
这个问题的本质是在考察你对延时任务解决方案的了解。类似的问题还有:
- 会议预定成功后,会议开始前 30 分钟通知所有预定该会议的用户,如何实现?
- 用户订单完成后未点击收货,10 天后自动同意收货,如何实现?
- 用户发起退款后,三天之内未被处理自动退款给用户,如何实现?
- ......
我这篇文章已经详细总结了定时和延时任务的常见解决方案:Java 定时任务详解 ,一定要看看。
单机延时任务方案有 Timer、ScheduledExecutorService、DelayQueue、Spring Task 和时间轮,其中最常用也是比较推荐使用的是时间轮。
MQ 延时任务
分布式延时任务的解决方案有 Redis 和 MQ。实际项目中,MQ 延时任务用的更多一些,可以降低业务之间的耦合度。大部分消息队列,例如 RocketMQ、RabbitMQ,都支持定时/延时消息。不过,在使用 MQ 定时/延时消息之前一定要看清楚其使用限制,以免不适合项目需求,例如 RocketMQ 定时时长最大值默认为 24 小时且不支持自定义修改、定时精度为秒。
如果你的项目没有用到 MQ 或者用到的 MQ 对延迟任务支持不好的话,Redis 延时任务也是可以考虑的。基于 Redis 实现延时任务的功能无非就下面两种方案:
- Redis 过期事件监听
- Redisson 内置的延时队列(推荐)
《后端面试高频系统设计&场景题》中有一篇文章详细介绍到这两种方案的优缺点,这里就不重复介绍了。
这里顺带分享一下 RabbitMQ 延迟队列的两种实现方式和选择,以及 RocketMQ 新版本对延时消息的优化,面试的时候能聊到就更好了。
RabbitMQ 延迟队列的两种实现方式:
- RabbitMQ 3.6.x 之前我们一般采用 DLX(Dead Letter Exchange,死信队列)+TLL(Time To Live,过期时间)。具体的原理是:将消息发送到一个设置了 TTL 的队列中,当消息过期后,会被转发到另一个设置了 DLX 的队列中,消费者监听这个 DLX 队列来获取延迟消息。
- RabbitMQ 3.6.x 开始,RabbitMQ 官方提供了延迟队列的插件 rabbitmq_delayed_message_exchange 。这种方式用的更多一些,比较简单方便,解决了 DLX+TLL 存在的一些问题(后面会提到)。通过这个插件,我们可以声明 x-delayed-message 类型的 Exchange(一种新的交换器类型),消息发送时指定消息头 x-delay 以毫秒为单位将消息进行延迟投递。这个插件支持的最大延迟时间是(2^32)-1 毫秒,大约 49 天。
DLX+TLL 这种方式存在一些问题比如:
- 存在消息阻塞问题 (主要问题):如果设置的是队列统一过期时间放到死信队列,那么就不会有阻塞问题,因为所有的消息都会在同一时间过期,然后被投递到死信队列。但是这种方案也有一个缺点,就是它不能实现不同的延迟时间,所有的消息都必须等待同样的时间才能被消费。如果是设置每条消息的 TTL 不同,那么可能会出现这阻塞问题。因为过期时间的检测也是从消息队列头部开始的,而队列又遵循先进先出,如果一个过期时间较长的消息在头部的话,可能就会导致阻塞其他过期时间较短的消息。
- 要为不同的延迟时间创建多个队列 :我们上面也说了队列统一过期时间可以解决头阻塞问题,但不能实现不同的延迟时间。如果想要实现不同的延迟时间,就需要单独为每一种过期时间创建一个对应的消息队列。如果延迟时间是动态可配置的,那么就需要动态地创建和删除队列。这样会增加系统复杂度、资源消耗和维护难度。而且,并不灵活,如果延迟时间是无规律的,那这种方式也不合适了。
- 不适合延迟时间较长的任务:会占用原队列和死信队列的空间。如果消息过期时间太长,那么它们就会在队列中存储很久,占用内存或磁盘空间。
更推荐 RabbitMQ 延迟队列插件这种方式。这种方式中,消息并不会立即进入队列,而是先把他们保存在 Mnesia 数据库(Erlang 运行时中自带的一个分布式数据库管理系统,详细介绍可参考Mnesia 数据库)中,然后通过一个定时器去查询需要被投递的消息,再把他们投递到 x-delayed-message 队列中。这种方式不存在消息阻塞问题,还可以实现灵活的延迟时间。并且,还避免过期时间太长的消息在队列中堆积,导致占用内存或磁盘空间。
RocketMQ 4.x 版本及其之前的版本支持基于预定义的延时等级的延时消息处理。消息发送者可以指定一个延时等级(如 1s、5s、10s 等),然后消息会在相应的延时级别到达后被发送到消费者队列。这些延时等级是固定的,不能灵活配置。
如下表所示,一共 18 个延时等级,具体时间如下:
| 投递等级(delay level) | 延迟时间 | 投递等级(delay level) | 延迟时间 |
|---|---|---|---|
| 1 | 1s | 10 | 6min |
| 2 | 5s | 11 | 7min |
| 3 | 10s | 12 | 8min |
| 4 | 30s | 13 | 9min |
| 5 | 1min | 14 | 10min |
| 6 | 2min | 15 | 20min |
| 7 | 3min | 16 | 30min |
| 8 | 4min | 17 | 1h |
| 9 | 5min | 18 | 2h |
RocketMQ 5.0 基于时间轮算法引入了定时消息,解决了延时级别只有 18 个、延时时间不准确等问题。RocketMQ 5.0 对延时消息的优化的详细介绍可以看看这篇文章:弥补延时消息的不足,RocketMQ 基于时间轮算法实现了定时消息!。
根据 RocketMQ 官方文档介绍:
- RocketMQ 定时消息的定时时长参数精确到毫秒级,但是默认精度为1000ms,即定时消息为秒级精度。
- RocketMQ 定时消息的状态支持持久化存储,系统由于故障重启后,仍支持按照原来设置的定时时间触发消息投递。若存储系统异常重启,可能会导致定时消息投递出现一定延迟。
下图是展示了一个基于 RocketMQ 的延时消息处理流程,结合了任务列表来管理和跟踪业务流程(该图来源于 RocketMQ 官方文档):
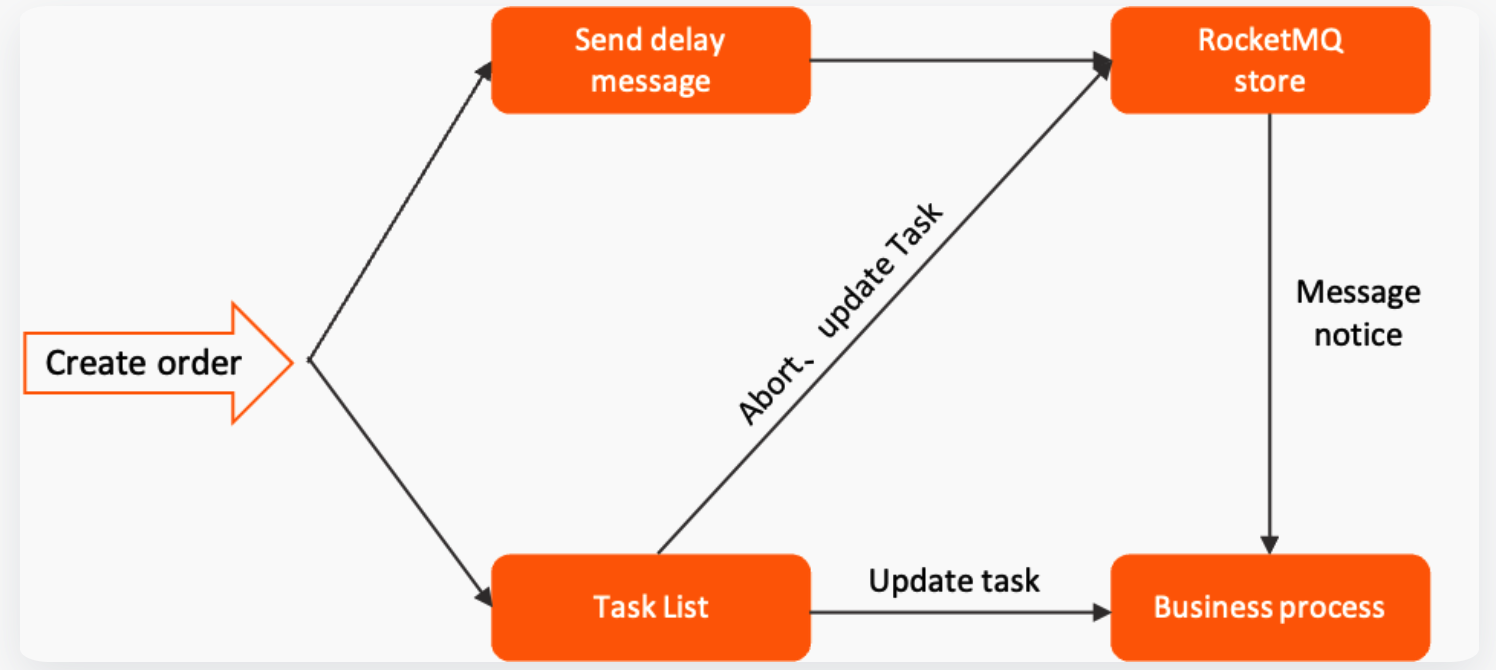
简单介绍一下上图包含的流程:
- 任务创建:任务创建后,会被添加到**任务列表(Task List)**中。任务列表通常是一个数据库表或其他持久化存储,用于记录和管理所有的任务,方便后续追踪任务的执行状态。
- 发送延时消息:在任务创建的同时,系统会向 RocketMQ 发送一条延时消息(Send delay message)。这条消息会在指定的时间后被触发,通常用于处理任务的超时逻辑或其他定时操作。
- RocketMQ 存储:延时消息会存储在 RocketMQ 的队列中,等待指定的延时结束后再被投递给消费者。
- 业务处理:在延时消息到达指定时间后,RocketMQ 会将消息投递给相应的消费者。消费者接收到消息后,会根据消息的内容触发相应的**业务处理(Business process)**逻辑。业务处理的结果可能会更新任务列表中的任务状态,或者直接进行其他的业务操作,比如取消订单、发送通知等。
- 任务列表更新:在任务处理过程中,任务列表会被更新。比如任务的状态可能会从“未处理”更新为“已处理”或“已超时”等等。任务列表的更新可以帮助系统追踪任务的执行状态,确保所有任务都得到了恰当的处理。
在使用 MQ 实现延时任务的时候,需要避免大量延时消息集中在同一时刻触发,这会给 MQ 带来巨大的压力,影响消息处理的及时性和延时精度。
不论是 RocketMQ 4.x 版本及其之前的版本还是 RabbitMQ 3.6.x 版本之前,在处理大时间跨度的任务时都存在一些问题,例如队列积压、时间跨度有限。
对于大时间跨度的任务,通过定时任务(例如 XXL-JOB、Spring Task)定期(如每 15 分钟或 30 分钟)扫描即将到期的任务并推送到 MQ 进行短时间延时处理,可以有效避免大时间跨度带来的问题,例如:
- 队列积压:如果直接将大时间跨度的任务放入 MQ 进行延时处理,消息可能会在队列中停留很长时间,可能导致消息积压。
- 时间跨度有限:RocketMQ 4.x 及之前的版本只有 18 个延时等级,最常支持两小时延时任务。RabbitMQ 的 TTL 是一个 32 位的带符号整数,单位是毫秒。这意味着 TTL 的最大值为 2147483647 毫秒,约等于 24.8 天。
- 消息丢失风险增加:在大时间跨度内,消息在 MQ 中停留的时间越长,越容易受到系统重启、网络波动、队列节点宕机等异常情况的影响,增加消息丢失的风险。
通过定时任务管理大时间跨度的任务,实际上是将任务的生命周期分成了两个阶段:
- 定时任务管理阶段: 任务处于“待处理”状态,定时任务定期扫描并识别即将到期的任务;
- MQ 处理阶段: 任务被精确地推送到 MQ 进行短时间延时处理。
在实现只推送即将到期的任务到消息队列(MQ)之前,通常需要一个持久化存储来保存这些任务,并通过定时任务定期扫描这些存储的数据。下面是一些可行的种持久化存储选择:
- 关系型数据库(常用):存储在关系型数据库(如 MySQL、PostgreSQL)中,记录任务的标识、内容、触发时间等数据。
- 缓存系统:存储在 Redis 这种分布式缓存中或者 Caffeine 这种本地缓存中,比较适合任务数量较少且时间跨度适当的场景,毕竟内存是昂贵的,任务数量较多会导致内存吃不消,时间跨度太大,任务就会一直保存在内存中占用内存,造成资源浪费。
数据库定时扫描 (DB Polling)
在某些场景下,如果系统架构相对简单,或者出于成本、复杂度考虑暂时不想引入 Redis、MQ 等外部中间件来专门处理延时任务,那么数据库定时扫描(DB Polling) 是一个非常直接且容易理解的备选方案。定时扫库方案如下:
- 记录过期时间戳: 在创建订单时(状态为“待支付”),直接在订单记录中增加一个字段,用于存储该订单的预计过期时间戳(例如,当前时间 + 24 小时)。
- 定时扫描数据库: 使用一个定时的数据库脚本或后台任务(可以通过
ScheduledExecutorService或 Spring Task 实现,也可以用分布式任务调度框架如 XXL-JOB、Elastic-Job、PowerJob 定期触发),周期性地(比如每分钟或每 5 分钟)扫描订单表。 - 更新过期订单: 扫描任务查询出满足
过期时间戳 <= 当前时间且订单状态 = '待支付'的订单,然后直接执行 UPDATE 语句将这些订单的状态更新为“已取消”。
在分布式环境下,为了避免多个应用实例重复扫描和处理,使用 ScheduledExecutorService 或 Spring Task 时需要搭配分布式锁。或者,也可以直接使用分布式任务调度框架(如 XXL-JOB, Elastic-Job, PowerJob)。《Java面试指北》的 SpingBoot 面试题总结这篇文章有详细提到这个问题:
这种方案实现简单,易于理解和维护。不过,频繁扫库会对数据库造成较大压力,数据量太大的情况下需要慎重选择此方案。并且,这种方案延时精度不高,订单取消的实际时间取决于扫描任务的执行频率,存在一定的延迟(最多一个扫描周期)。还可能会存在资源浪费 (空轮询)问题, 也就是存在大量扫描周期内并没有找到任何到期任务的情况,这会造成一定的计算和数据库 IO 资源浪费。
需要明确的是,像 XXL-JOB、Elastic-Job、PowerJob 这类分布式任务调度框架,在这个“定时扫库”方案中,通常扮演的是**触发器(Trigger)**的角色——即按预设的周期(如每分钟)准时地启动那个负责扫描数据库的任务程序。
虽然这些框架本身也能创建一次性的、指定未来某个时间点执行的任务(从而模拟延时效果),但它们的设计初衷更侧重于周期性、计划性的任务调度(比如每日报表、定时同步等)。如果直接用它们来管理海量的、触发时间点各异的延时任务(例如,为每个订单都创建一个单独的延时调度任务),可能会遇到以下问题:
- 时间精度可能不够理想: 调度本身可能有秒级甚至更粗粒度的延迟。
- 对调度中心造成过大压力: 管理大量细碎的一次性任务可能消耗过多调度资源。
- 性能可能无法满足高并发需求: 调度和执行大量并发到期的任务可能成为瓶颈。
这些框架的核心优势在于处理周期性任务,并提供分布式环境下的任务分片、高可用保障、失败重试、以及强大的可视化管理和监控界面。
更新: 2025-12-10 14:52:20
原文: https://www.yuque.com/snailclimb/tangw3/sgageiesw7cqi1o7