《深入剖析 Java 新特性》
介绍:《深入剖析 Java 新特性》 读书笔记。
作者:Guide 哥
拥抱 Java 新特性
为什么要学习 Java 新特性?
- 写出来的代码质量更高,性能更好(保守粗暴的估计项目整体质量至少可以提升 20%)!
- 主流企业很快就会拥抱 JDK 11 或者 JDK 17,就像它们曾经拥抱过 JDK 7 或者 JDK 8 一样。你没必要等到真正用到的时候再学。
- 工程师要乐于拥抱新技术,而不是抵触。
试着像 Java 语言的设计者一样思考
在设计新特性时,我们还要考量这项新特性是否能够持续地满足:
- 新的需求(Requirement)
- 增强代码安全(Security)
- 提高生产效率(Productivity )
- 提升产品性能(Performance)
- 降低维护成本(Maintenance)。
试着从新特性设计者的角度来了解和学习这些新特性,这会让你学得更快、更精准、更深入,减少自己摸索的过程,更快地获得竞争的优势。
这门课会带我们学习哪些新特性?
JDK 9 到 JDK 17 的新特性中最核心、有用的 18 条特性:
- 第一个模块 :介绍一些可以提升编码效率的特性,比如说档案类。
- 第二个模块 :介绍一些提升代码性能的特性,比如错误处理的最新成果。
- 第二个模块 :介绍如何通过新特性降低维护难度,比如模块化和安全性、兼容性问题。
如何知道自己是否学好了这些新特性?
很简单的判断标准:面试聊得开,代码写得好,技术用得上。
提升编码效率
JShell:怎么快速验证简单的小问题?
面试问题:
你使用过 JShell 吗?JShell 为我们带来了哪些好处呢?
JShell 的代码和普通的可编译代码,有什么不一样?
JShell 这个特性在 JDK 9 正式发布。简单来说,JShell 就是 Java 脚本语言,为 Java 提供了类似于 Python 的实时命令行交互体验。
在 Jshell 中可以直接输入表达式并查看其执行结果。
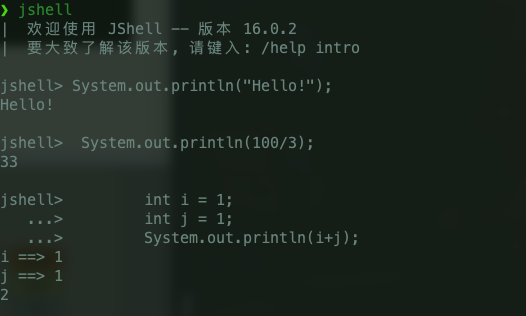
JShell 为我们带来了哪些好处呢?
- 降低了输出第一行 Java 版"Hello World!"的门槛,能够提高新手的学习热情。
- 在处理简单的小逻辑,验证简单的小问题时,比 IDE 更有效率(并不是为了取代 IDE,对于复杂逻辑的验证,IDE 更合适,两者互补)。
- ......
JShell 的代码和普通的可编译代码,有什么不一样?
- 一旦语句输入完成,JShell 立即就能返回执行的结果,而不再需要编辑器、编译器、解释器。
- JShell 支持变量的重复声明,后面声明的会覆盖前面声明的。
- JShell 支持独立的表达式比如普通的加法运算
1 + 1。 - ......
文本块:怎么编写所见即所得的字符串?
面试问题:
你知道 Java 的文本块吗?它和字符串有什么区别?了解文本块要解决的问题,并且能够准确使用文本块;
应当什么时候使用文本块?了解文本块的表达形式,编译过程以及文本块特有的转义字符。
文本块如何表示长段落和空格?
文本块这个特性,首先在 JDK 13 中以预览版的形式发布。在 JDK 14 中,改进的文本块再次以预览版的形式发布。最后,文本块在 JDK 15 正式发布。
没有文本块之前,我们需要构造一个一个简单的表示"Hello,World!"的 HTML 字符串。
// 不好写,不好看,也不好读
String stringBlock =
"<!DOCTYPE html>\n" +
"<html>\n" +
" <body>\n" +
" <h1>\"Hello World!\"</h1>\n" +
" </body>\n" +
"</html>\n";有了文本块之后:
// 易读,好写,好读
String textBlock = """
<!DOCTYPE html>
<html>
<body>
<h1>"Hello World!"</h1>
</body>
</html>
""";
System.out.println(
"Here is the text block:\n" + textBlock);像传统的字符串一样,文本块是字符串的一种常量表达式。不同于传统字符串的是,在编译期,文本块要顺序通过如下三个不同的编译步骤:
- 为了降低不同平台间换行符的表达差异,编译器把文字内容里的换行符统一转换成 LF(\u000A);
- 为了能够处理 Java 源代码里的缩进空格,要删除所有文字内容行和结束分隔符共享的前导空格,以及所有文字内容行的尾部空格;
- 最后处理转义字符,这样开发人员编写的转义序列就不会在第一步和第二部被修改或删除。
下面我们来看一个案例:
public class TextBlocks {
public static void main(String[] args) {
String stringBlock =
"<!DOCTYPE html>\n" +
"<html>\n" +
" <body>\n" +
" <h1>\"Hello World!\"</h1>\n" +
" </body>\n" +
"</html>\n";
String textBlock = """
<!DOCTYPE html>
<html>
<body>
<h1>"Hello World!"</h1>
</body>
</html>
""";
System.out.println(
"Does the text block equal to the regular string? " +
stringBlock.equals(textBlock));
System.out.println(
"Does the text block refer to the regular string? " +
(stringBlock == textBlock));
}
}思考一下:这两个字符串变量指向的是同一个对象,还是不同的对象?
答案:使用传统方式声明的字符串和使用文本块声明的字符串,它们的内容是一样的,而且指向的是同一个对象。
为什么呢? 因为文本块是在编译期处理的,并且在编译期被转换成了常量字符串,然后就被当作常规的字符串了。
虽然表达形式不同,但是文本块就是字符串。既然是字符串,就能够使用字符串支持的各种 API 和操作方法。 比如,传统的字符串表现形式和文本块的表现形式可以混合使用:
int stringSize = """
<!DOCTYPE html>
<html>
<body>
<h1>"Hello World!"</h1>
</body>
</html>
""".length();文本块如何表示长段落? 通过换行转义符 \ 即可。
String str = "凡心所向,素履所往,生如逆旅,一苇以航。";
String str2 = """
凡心所向,素履所往, \
生如逆旅,一苇以航。""";
// 凡心所向,素履所往, 生如逆旅,一苇以航。
System.out.println(str2);**如何表示空格? ** 通过空格转义符 \s 即可。
String text = """
java
c++\sphp
""";
System.out.println(text);
//输出:
java
c++ php档案类:怎么精简地表达不可变数据?
面试问题:
你知道档案类吗?会不会使用它?
什么情况下可以使用档案类,什么情况下不能使用档案类?
使用档案类应该注意什么问题?
档案类(record)这个特性,首先在 JDK 14 中以预览版的形式发布。在 JDK 15 中,改进的档案类再次以预览版的形式发布。最后,档案类在 JDK 16 正式发布。
Java 档案类是用来表示 不可变数据 (数据类,一个 Java 类一旦实例化就不能再修改)的透明载体。
/**
* 这个类具有两个特征
* 1. 所有成员属性都是final
* 2. 全部方法由构造方法,和两个成员属性访问器组成(共三个)
* 那么这种类就很适合使用 record 来声明
*/
final class Rectangle implements Shape {
final double length;
final double width;
public Rectangle(double length, double width) {
this.length = length;
this.width = width;
}
double length() { return length; }
double width() { return width; }
}
record Rectangle(float length, float width) implements Shape { }Java 档案类还做了以下的限制:
- Java 档案类是个终极(final)类,不支持子类,也不能是抽象类。没有子类,也就意味着我们不能通过修改子类来改变 Java 档案的行为。
- Java 档案类声明的变量是不可变的变量。这就是我们前面反复强调的,一旦实例化就不能再修改的关键所在。
- Java 档案类不能声明可变的变量,也不能支持实例初始化的方法。这就保证了,我们只能使用档案类形式的构造方法,避免额外的初始化对可变性的影响。
- Java 档案类不能声明本地(native)方法。如果允许了本地方法,也就意味着打开了修改不可变变量的后门。
档案类内置了构造方法、不可变数据的读取方法、 toString()、hashCode()、 equals() 的缺省实现 。我们可以使用缺省的实现,也可以替换掉缺省的实现(用 Override 注解来标注被替换的缺省的实现)。
public record Rectangle(float length, float width) implements Shape {
@Override
public String toString() {
return String.format("Circle[radius=%f]", radius);
}
}封闭类:怎么刹住失控的扩展性?
面试问题:
你知道封闭类吗?会不会使用它?
面向对象编程的可扩展性有什么问题吗?该怎么处理这些问题?
你写的这段代码,是不是应该使用 final 修饰符或者 sealed 修饰符?
JDK 17 之前的 Java 语言,限制住类的可扩展性只有两个方法:
- 私有类 : 一般是私有内部类,仅在声明这个私有内部类的类的内部使用。
final** 修饰符** : 彻底放弃了可扩展性。
JDK 17 之后,我们可以用 sealed 关键字来修饰类(封闭类)或者接口(封闭接口)。封闭类和封闭接口限制可以扩展或实现它们的其他类或接口。
封闭类(sealed classes)这个特性,首先在 JDK 15 中以预览版的形式发布。在 JDK 16 中,改进的封闭类再次以预览版的形式发布。最后,封闭类在 JDK 17 正式发布。
举例:抽象类 Person 只允许 Employee 和 Manager 继承。
public abstract sealed class Person
permits Employee, Manager {
//...
}另外,任何扩展封闭类的类本身都必须声明为 sealed、non-sealed 或 final。
public final class Employee extends Person {
}
public non-sealed class Manager extends Person {
}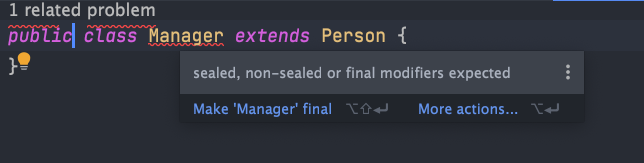
如果允许扩展的子类和封闭类在同一个源代码文件里,封闭类可以不使用 permits 语句,Java 编译器将检索源文件,在编译期为封闭类添加上许可的子类。
类型匹配:怎么切除臃肿的强制转换?
面试问题:
你知道类型匹配吗?会不会使用它?
使用类型匹配有哪些好处?匹配变量什么时候可以使用?
你写的这段代码(如果使用了类型匹配),还有更好的表达方式吗?
相关阅读:Java 新特性解析:模式匹配
Java 的模式匹配是一个新型的、而且还在持续快速演进的领域。类型匹配是模式匹配的一个规范。
类型匹配 这个特性,首先在 JDK 14 中以预览版的形式发布。在 JDK 15 中,改进的类型匹配再次以预览版的形式发布。最后,类型匹配在 JDK 16 正式发布。
小案例:我们要设计一个方法,来判断一个形状是不是正方形。
// 没有类型匹配之前
// 类型判断和类型转换分为两部分,增加了出错的可能性
static boolean isSquare(Shape shape) {
if (shape instanceof Rectangle) {
Rectangle rect = (Rectangle) shape;
return (rect.length == rect.width);
}
return (shape instanceof Square);
}
// 有了类型匹配之后
// 型判断和类型转换一行代码解决,减少了出错的可能性,并且代码更优雅
if (shape instanceof Rectangle rect) {
return (rect.length == rect.width);
}匹配变量的作用域 就是目标变量可以被确认匹配的范围。如果在一个范围内,无法确认目标变量是否被匹配,或者目标变量不能被匹配,都不能使用匹配变量。 如果我们从编译器的角度去理解,也就是说,在一个范围里,如果编译器能够确定匹配变量已经被赋值了,那么它就可以在这个范围内使用;如果编译器不能够确定匹配变量是否被赋值,或者确定没有被赋值,那么他就不能在这个范围内使用。
// 如果模式匹配出现在 if 语句的头部,变量绑定将出现在 if 语句其中的一个分支中,而不是同时出现在两个分支中
if (x instanceof Foo f) {
// f in scope here
}
else {
// f not in scope here
}类似地:
if (!(x instanceof Foo f)) {
// f not in scope here
}
else {
// f in scope here
}有人可能会想:既然我们可以继续使用传统的“作用域一直到块的末尾”规则,为什么要选择这种更复杂的作用域方法。 答案是:我们可以这样,但我们可能并不喜欢这样的结果。
如果作用域一直到块的末尾,那么对于下面这样的情况,我们就需要重新声明 num,不得不为每一个分支使用一个新的名字(switch 中的 case 标签模式也是如此)。
Object x = getDouble();
// 通过在执行 else 时将 num 置于作用域之外,我们可以在 else 子句中自由地重新声明一个新的 num(具有新的类型)。
if (x instanceof Integer num) {
System.out.println(num);
} else if (x instanceof Long num) {
System.out.println(num);
} else if (x instanceof Double num) {
System.out.println(num);
}
private static Object getDouble() {
return Integer.valueOf("2");
}switch 表达式:怎么简化多情景操作?
面试题:
你知道 switch 表达式吗?该怎么处理 switch 表达式里的语句?
使用 switch 表达式有哪些好处?
你更喜欢使用箭头标识符还是冒号标识符?
switch 表达式这个特性,首先在 JDK 12 中以预览版的形式发布。在 JDK 13 中,改进的 switch 表达式再次以预览版的形式发布。最后,switch 表达式在 JDK 14 正式发布。
现在,我们需要写一个计算每个月有多少天的代码,让我们来看看 switch 表达式增强之前和增强之后的写法。
没有增强 switch 表达式之前 :
class DaysInMonth {
public static void main(String[] args) {
Calendar today = Calendar.getInstance();
int month = today.get(Calendar.MONTH);
int year = today.get(Calendar.YEAR);
int daysInMonth;
switch (month) {
case Calendar.JANUARY:
case Calendar.MARCH:
case Calendar.MAY:
case Calendar.JULY:
case Calendar.AUGUST:
case Calendar.OCTOBER:
case Calendar.DECEMBER:
daysInMonth = 31;
break;
case Calendar.APRIL:
case Calendar.JUNE:
case Calendar.SEPTEMBER:
case Calendar.NOVEMBER:
daysInMonth = 30;
break;
case Calendar.FEBRUARY:
if (((year % 4 == 0) && !(year % 100 == 0))
|| (year % 400 == 0)) {
daysInMonth = 29;
} else {
daysInMonth = 28;
}
break;
default:
throw new RuntimeException(
"Calendar in JDK does not work");
}
System.out.println(
"There are " + daysInMonth + " days in this month.");
}
}容易出错的点:
break关键字使用不当可以导致代码逻辑出错。daysInMonth这个本地变量的变量声明和实际赋值是分开的。赋值语句需要反复出现,以适应不同的情景。如果在 switch 语句里,daysInMonth变量没有被赋值,编译器也不会报错,缺省的或者初始的变量值就会被使用。
简单来说,没有增强 switch 表达式之前的写法增加了编码出错的几率,也增加了阅读代码的成本。
增强 switch 表达式之后的代码如下 :
class DaysInMonth {
public static void main(String[] args) {
Calendar today = Calendar.getInstance();
int month = today.get(Calendar.MONTH);
int year = today.get(Calendar.YEAR);
int daysInMonth = switch (month) {
case Calendar.JANUARY,
Calendar.MARCH,
Calendar.MAY,
Calendar.JULY,
Calendar.AUGUST,
Calendar.OCTOBER,
Calendar.DECEMBER -> 31;
case Calendar.APRIL,
Calendar.JUNE,
Calendar.SEPTEMBER,
Calendar.NOVEMBER -> 30;
case Calendar.FEBRUARY -> {
if (((year % 4 == 0) && !(year % 100 == 0))
|| (year % 400 == 0)) {
// yield 语句产生的值看成是 switch 表达式的返回值
yield 29;
} else {
yield 28;
}
}
default -> throw new RuntimeException(
"Calendar in JDK does not work");
};
System.out.println(
"There are " + daysInMonth + " days in this month.");
}
}带来的好处:
- 引入了类似 lambda 语法条件匹配成功后的执行块,不需要多写 break(箭头标识符右侧可以是表达式、代码块或者异常抛出语句);
- 一个 case 语句,可以处理多个情景;
- switch 代码块变成了一个表达式,可以有返回值;
简单来说,switch 语句的改进主要体现在 break 语句的使用上,增强 switch 表达式之后的写法减少了编码出错的几率,也降低了阅读代码的成本。
switch 匹配:能不能适配不同的类型?
面试题:
你知道怎么使用 switch 匹配不同的类型吗?
使用 switch 的模式匹配有哪些好处?
子类扩充有可能遇到什么问题,该怎么解决?
switch 的模式匹配这个特性,在 JDK 17 还是预览版。你可以现在开始学习这个特性,但是暂时不要把它用在正式的项目里,直到正式版发布。
具有模式匹配能力的 switch,提升了 switch 的数据类型匹配能力。 switch 要匹配的数据,现在可以是整形的原始类型(数字、枚举、字符串),或者引用类型,甚至是空引用“null”。
// 判断一个对象是不是正方形
public static boolean isSquare(Shape shape) {
return switch (shape) {
case null, Shape.Circle c -> false;
case Shape.Square s -> true;
};
}并且,具有模式匹配能力的 switch(包括 switch 语句和 switch 表达式),还提高了多情景处理性能。 寻找匹配情景时,switch 并不需要按照 case 语句的顺序执行。对于 switch 的处理方式,找到匹配的情景的时间复杂度是 O(1) (if-else 的处理方式的时间复杂度是 O(N))。
另外,switch 表达式还大大地降低了代码维护的难度,让我们有更多的精力专注在更有价值的问题上。这是因为 switch 表达式需要穷举出所有的情景。否则,编译器就会报错。
什么时候使用 default?
switch 表达式总是能够穷举出所有的情景,不过,这样 switch 代码失去了检测匹配情景有没有变更的能力。
public static boolean isSquare(Shape shape) {
return switch (shape) {
case Shape.Square s -> true;
case null, default -> false;
};
}一般来说,只有我们能够确信,待匹配类型的升级,不会影响 switch 表达式的逻辑的时候,我们才能考虑使用缺省选择情景。
子类扩充有可能遇到什么问题,该怎么解决?
子类扩充出现的兼容性问题,是面向对象编程实践中一个棘手、重要、高频的问题。如果你能够有意识地使用 switch 的模式匹配,并且编写的代码能够自动检测到子类扩充出现的变动,就可以降低代码的维护难度和维护成本,提高代码的健壮性。在面试的时候,如果你能够主动地在代码里使用 switch 的模式匹配,而不是传统的 if-else 语句,这会是一个震惊面试官的好机会。
如果你想要丰富你的代码评审清单,有了 switch 的模式匹配以后,你可以加入下面这几条:
- 处理情景选择的 if-else 语句,是不是可以使用 switch 的模式匹配?
- 使用了模式匹配的 switch 表达式,有没有必要使用缺省选择情景 default?
- 使用了模式匹配的 switch 语句和表达式,是不是可以使用 null 选择情景?
- 基于 map 策略模式的场景是不是可以用 switch 表达式代替?
提高代码性能
面试题:
你知道 Java 异常处理会产生什么问题吗(清楚 Java 异常处理所带来的性能问题,对这一问题的影响程度有一个大致的概念)?
你知道怎么提高 Java 代码的性能吗(从 Java 异常处理的替代方案的优势和劣势这个角度来说)?
抛出异常,是不是错误处理的第一选择?
通常情况下,如果业务逻辑出现了问题,比如说用户输入的数据不合规范,我们都会抛出一个异常。我们的服务器会捕获所有的异常,不管是运行时异常,还是检查型异常;然后从异常中恢复过来,继续提供服务。
为什么要重视 Java 异常处理?
因为 Java 异常的使用和处理,是滥用最严重,诟病最多,也是最难平衡的一个难题。为了解决花样百出的 Java 错误处理问题,也有过各种各样的办法。然而,到目前为止,我们还没有看到能解决所有问题的好方法,这也是编程语言研究者们的努力方向。
异常处理对代码执行效率的影响有多大呢?
我们通过下面这段截取一段字符串的代码来看看有异常处理和没有异常处理对代码执行效率的影响。
public class OutOfBoundsBench {
private static String s = "Hello, world!"; // s.length() == 13.
@Benchmark
public void withException() {
try {
s.substring(14);
} catch (RuntimeException re) {
// blank line, ignore the exception.
}
}
@Benchmark
public void noException() {
try {
s.substring(13);
} catch (RuntimeException re) {
// blank line, ignore the exception.
}
}
}基准测试结果:
Benchmark Mode Cnt Score Error Units
OutOfBoundsBench.noException thrpt 15 566348609.338 ± 22165278.114 ops/s
OutOfBoundsBench.withException thrpt 15 504193.920 ± 26489.992 ops/s从基准测试结果可以看出:没有抛出异常的用例,它能够支持的吞吐量要比抛出异常的用例大 1000 倍。
既然异常处理的效率这么让人揪心,我们编写的 Java 代码能够像 Go 语言一样重回错误码方式吗?
使用错误码改造前:
import java.security.NoSuchAlgorithmException;
public sealed abstract class Digest {
public static Digest of(String algorithm) throws NoSuchAlgorithmException {
return switch (algorithm) {
case "SHA-256" -> new SHA256();
case "SHA-512" -> new SHA512();
default -> throw new NoSuchAlgorithmException();
};
}
}使用错误码改造后:
public record Coded<T>(T returned, int errorCode) {
// blank
};
public static Coded<Digest> of(String algorithm) {
return switch (algorithm) {
case "SHA-256" -> new Coded(sha256, 0);
case "SHA-512" -> new Coded(sha512, 0);
default -> new Coded(null, -1);
};
}对应地,这个方法的使用就需要处理错误码。下面的代码,就是一个该怎么使用错误码的例子。
Coded<Digest> coded = Digest.of("SHA-256");
if (coded.errorCode() != 0) {
// snipped
} else {
coded.returned().digest("Hello, world!".getBytes());
}使用错误码之后,经过基准测试我们发现:没有返回错误码的用例,它能够支持的吞吐量和返回错误码的用例几乎没有差别。
错误码的形式优化了性能却放弃了代码的可读性和可维护性。 为什么这么说呢?
1、由于异常的分层设计,所有的异常都是 Exception 的子类;我们也就可以一次性地处理多个方法抛出的异常了:
try {
doSomething(); // could throw Exception
doSomethingElse(); // could throw RuntimeException
socket.close(); // could throw IOException
} catch (Exception ex) {
// handle the exception in one place.
}如果使用了错误码的方式,每一个方法调用都要检查返回的错误码。一般情况下,同样的逻辑和接口结构,使用错误码的方式需要编写更多的代码。
对于简单的逻辑和语句,我们可以使用逻辑运算符合并多个语句。这种紧凑的方式,牺牲了代码的可读性,不是我们喜欢的编码风格。
if (doSomething() != 0 &&
doSomethingElse() != 0 &&
socket.close() != 0) {
// handle the exception
}对于复杂的逻辑和语句来说,紧凑的方式就行不通了。这时候,就需要一个独立的代码块来处理错误码。
if (doSomething() != 0) {
// handle the exception
};
if (doSomethingElse() != 0) {
// handle the exception
};
if (socket.close() != 0) {
// handle the exception
}2、重回错误码最大的代价,是可维护性大幅度降低。使用异常的代码,我们能够通过异常的调用堆栈,清楚地看到代码的执行轨迹,快速找到出问题的代码。这也是我们使用异常处理的主要动力之一。
Exception in thread "main" java.security.NoSuchAlgorithmException: \
Unsupported digest algorithm SHA-128
at co.ivi.jus.agility.former.Digest.of(Digest.java:31)
at co.ivi.jus.agility.former.NoCatchCase.main(NoCatchCase.java:12)C 语言时代的错误码,和 Java 语言时代的异常处理机制,就像是跷跷板的两端,一端是性能,一端是可维护性。
使用错误码,也有一条铁的纪律:必须首先检查错误码,然后才能使用返回值。
下面这段代码就是一个改进的设计:
public sealed interface Returned<T> {
record ReturnValue<T>(T returnValue) implements Returned {
}
record ErrorCode(Integer errorCode) implements Returned {
}
}相比较使用 Coded 档案类的例子,这里的返回值和错误码分离开了。这样就可以让一个方法,返回的要么是返回值,要么是错误码,而不是同时返回两个值。
public static Returned<Digest> of(String algorithm) {
return switch (algorithm) {
case "SHA-256" -> new ReturnValue(new SHA256());
case "SHA-512" -> new ReturnValue(new SHA512());
case null, default -> new ErrorCode(-1);
};
}这样的话,我们只有在返回值是错误码的情况下才需要去检查错误码。
异常恢复,付出的代价能不能少一点?
面试题:
你的代码是怎么处理 Java 异常的(了解可恢复异常和不可恢复异常这两个概念,以及它们的使用场景)?
你的代码,是怎么定位可能存在的问题的(了解怎么在使用错误码的方案里,添加快速定位出问题的调试信息)?
有没有可能改进 Java 的异常处理,保持它在错误排查方面的优势的同时,提高它的性能呢?
我们使用异常的形式补充了调试信息,包括问题描述和调用堆栈:
public static Returned<Digest> of(String algorithm) {
return switch (algorithm) {
case "SHA-256" -> new Returned.ReturnValue(new SHA256());
case "SHA-512" -> new Returned.ReturnValue(new SHA512());
case null -> {
System.getLogger("co.ivi.jus.stack.union")
.log(System.Logger.Level.WARNING,
"No algorithm is specified",
new Throwable("the calling stack"));
yield new Returned.ErrorCode(-1);
}
default -> {
System.getLogger("co.ivi.jus.stack.union")
.log(System.Logger.Level.INFO,
"Unknown algorithm is specified " + algorithm,
new Throwable("the calling stack"));
yield new Returned.ErrorCode(-1);
}
};
}方法调用的时候,我们还补充了调用场景的信息:
Returned<Digest> rt = Digest.of("SHA-128");
switch (rt) {
case Returned.ReturnValue rv -> {
Digest d = (Digest) rv.returnValue();
d.digest("Hello, world!".getBytes());
}
case Returned.ErrorCode ec ->
System.getLogger("co.ivi.jus.stack.union")
.log(System.Logger.Level.INFO,
"Failed to get instance of SHA-128");
}经过这样的调整,类似于使用异常处理的、快速定位出问题的调试信息就又回来了。
Nov 05, 2021 10:08:23 PM co.ivi.jus.stack.union.Digest of
INFO: Unknown algorithm is specified SHA-128
java.lang.Throwable: the calling stack
at co.ivi.jus.stack.union.Digest.of(Digest.java:37)
at co.ivi.jus.stack.union.UseCase.main(UseCase.java:10)
Nov 05, 2021 10:08:23 PM co.ivi.jus.stack.union.UseCase main
INFO: Failed to get instance of SHA-128使用调试信息带来的性能损失,并不比使用异常性能的损失小多少。不过好在,日志记录既可以开启,又可以关闭。如果我们关闭了日志,就不用再生成调试信息了,当然它的性能影响也就消失了。当需要我们定位问题的时候,再启动日志。这时候,我们就能够把性能的影响控制到一个极小的范围内了。
Flow,是异步编程的终极选择吗
面试题:
你知道声明式编程模型吗,它是怎么工作的(了解指令式编程模型和声明式编程模型这两个术语)?
你知道怎么使用 Java 反应式编程模型吗(了解 Java 反应式编程模型的基本组件,以及它们的组合方式)?
你知道回调函数有什么问题吗(知道回调函数的形式,以及回调地狱这个说法)?
相关阅读:
Reactive Programming with Java 9's Flow(写的非常好!通过案例讲解,非常易懂)
为什么使用 Reactive 之反应式编程简介 (KL 大佬的一篇原创)
反应式编程曾经是一个很热门的话题。它是代码的控制的一种模式。如果不分析其他的模式,我们很难识别反应式编程的好与坏,以及最合适它的使用场景。
关于常见的编码模型解读,请看 编程模型(范式)小结 这篇文章。
为什么要学习反应式编程? 反应式编程是目前主流的支持高并发的技术架构思路。学会反应式编程,意味着你有能力处理高并发应用这样的需求。能够编写高并发的代码,现在很重要,以后更重要。学会使用 Java 反应式编程模型这样一个高度抽象的接口,毫无疑问能够提升你的技术深度。
反应式编程它的关注点转移到了数据的变化以及数据和变化的传递上,或者说,是转移到了对数据变化的反应上。所以,反应式编程的核心是数据流和变化传递。
如果我们从数据的流向角度来看的话,数据有两种基本的形式:
- 数据的输入
- 数据的输出。
从这两种基本的形式,能够衍生出三种过程:最初的来源 —> 数据的传递 —> 最终的结局。
数据输出
在 Java 的反应式编程模型的设计里,数据的输出使用只有一个参数的 Flow.Publisher 来表示。
@FunctionalInterface
public static interface Publisher<T> {
// 订阅者的订阅行为,是由数据的发布者发起的,而不是订阅者发起的。
public void subscribe(Subscriber<? super T> subscriber);
}数据的发布者通过授权订阅者,来实现数据从发布者到订阅者的传递。一个数据的发布者,可以有多个数据的订阅者。
数据的输入
Flow.Subscriber 接口一共定义了四种任务,并分别规定了下面四种情形下的反应:
- 如果接收到订阅邀请该怎么办?这个行为由
onSubscribe这个方法的实现确定。 - 如果接收到数据该怎么办?这个行为由
onNext这个方法的实现确定。 - 如果遇到了错误该怎么办?这个行为由
onError这个方法的实现确定。 - 如果数据传输完毕该怎么办?这个行为由
onComplete这个方法的实现确定。
public static interface Subscriber<T> {
// 处理收到订阅邀请
public void onSubscribe(Subscription subscription);
// 处理接收的数据
public void onNext(T item);
// 处理出现错误的情况
public void onError(Throwable throwable);
// 数据传输完毕之后执行的方法
public void onComplete();
}数据的控制
Flow.Subscription用于将 Flow.Subscriber和Flow.Subscriber联系起来。
public static interface Subscription {
// 订阅者希望接收的数据数量
public void request(long n);
// 订阅者希望取消订阅
public void cancel();
}数据的传递
在 Java 中,数据的传递由Flow.Processor 负责。
Flow.Processor 是一个扩展了 Flow.Publisher 和 Flow.Subscriber 的接口。所以,Flow.Processor 有两个数据类型,泛型 T 表述输入数据的类型,泛型 R 表述输出数据的类型。
public static interface Processor<T,R> extends Subscriber<T>, Publisher<R> {
}下面的代码,就是一个表示数据传递的例子。在这段代码里,我们使用泛型来表示输入数据和输出数据的类型;然后,我们使用了一个 Function 函数,来表示该怎么处理接收到的数据,并且输出处理的结果。
import java.util.concurrent.Flow;
import java.util.concurrent.SubmissionPublisher;
import java.util.function.Function;
public class Transform<T, R> extends SubmissionPublisher<R>
implements Flow.Processor<T, R> {
private Function<T, R> transform;
private Flow.Subscription subscription;
public Transform(Function<T, R> transform) {
super();
this.transform = transform;
}
@Override
public void onSubscribe(Flow.Subscription subscription) {
this.subscription = subscription;
subscription.request(1);
}
@Override
public void onNext(T item) {
submit(transform.apply(item));
subscription.request(1);
}
@Override
public void onError(Throwable throwable) {
closeExceptionally(throwable);
}
@Override
public void onComplete() {
close();
}
}过程的串联
下面的代码,就是我们试图把最初的来源、数据的传递和最终的结局这三个过程,串联成一个更大的过程的例子。当然,你也可以试着串联进更多的数据处理过程。
private static void transform(byte[] message,
Function<byte[], byte[]> transformFunction) {
SubmissionPublisher<byte[]> publisher =
new SubmissionPublisher<>();
// Create the transform processor
Transform<byte[], byte[]> messageDigest =
new Transform<>(transformFunction);
// Create subscriber for the processor
Destination<byte[]> subscriber = new Destination<>(
values -> System.out.println(
"Got it: " + Utilities.toHexString(values)));
// Chain processor and subscriber
publisher.subscribe(messageDigest);
messageDigest.subscribe(subscriber);
publisher.submit(message);
// Close the submission publisher.
publisher.close();
}外部内存接口:零拷贝的障碍还有多少?
Java 的外部内存接口这个新特性,非常非常重要,不过,现在还在孵化期。
在我们讨论代码性能的时候,内存的使用效率是一个绕不开的话题。
像 TensorFlow、 Ignite、 Flink 以及 Netty 这样的类库,为了避免 Java 垃圾收集器不可预测的行为以及额外的性能开销,这些产品一般倾向于使用 JVM 之外的内存来存储和管理数据。这样的数据,就是我们常说的 堆外数据(off-heap data) 。
使用堆外存储最常用的办法,就是使用 ByteBuffer 这个类来分配直接存储空间(direct buffer)。 JVM 虚拟机会尽最大努力直接在直接存储空间上执行 IO 操作,避免数据在本地和 JVM 之间的拷贝。
由于频繁的内存拷贝是性能的主要障碍之一。所以为了极致的性能,应用程序通常也会尽量避免内存的拷贝。理想的状况下,一份数据只需要一份内存空间,这就是我们常说的零拷贝。
下面的这段代码,就是用 ByteBuffer 这个类来分配直接存储空间的方法
public static ByteBuffer allocateDirect(int capacity);不过,ByteBuffer 存在两个明显的缺陷:
- 没有资源释放的接口。
- 存储空间尺寸的限制。
ByteBuffer的存储空间的大小,是使用 Java 的整数来表示的。所以,它的存储空间,最多只有 2G。2G 以上的文件,映射到ByteBuffer上的时候,就会出现文件过大的问题。
对于第一个缺陷,我们还可以在 ByteBuffer 的基础上修改,并且保持这个类的优雅。但是第二个缺陷,由于 ByteBuffer 类里到处都在使用的整数类型,我们就很难找到办法既保持这个类的优雅,又能够突破存储空间的尺寸限制了。
一个合理的改进,就是重新建造一个轮子。这个新的轮子,就是 外部内存接口 。
外部内存接口沿袭了 ByteBuffer 的设计思路,但是使用了全新的接口布局。我们先来看看使用外部内存接口的代码看起来是什么样子的。
// 分配一段外部内存,并且存放 4 个字母 A。
try (ResourceScope scope = ResourceScope.newConfinedScope()) {
MemorySegment segment = MemorySegment.allocateNative(4, scope);
for (int i = 0; i < 4; i++) {
MemoryAccess.setByteAtOffset(segment, i, (byte)'A');
}
}ResourceScope: 定义了内存资源的生命周期管理机制。并且,还实现了AutoCloseable接口,我们就可以使用try-with-resource这样的语句,及时地释放掉它管理的内存了。这样的设计,就解决了ByteBuffer的第一个缺陷。MemorySegment: 定义和模拟了一段连续的内存区域。MemoryAccess: 定义了可以对MemorySegment执行读写操作。
在 ByteBuffer 的设计里,内存的表达和操作,是在 ByteBuffer 这一个类里完成的。在外部内存接口的设计里,把对象表达和对象的操作,拆分成了两个类。这两类的寻址数据类型,使用的是长整形(long)。这样,长整形的寻址类型,就解决了 ByteBuffer 的第二个缺陷。
外部函数接口:能不能取代 Java 本地接口?
Java 的外部函数接口(Java Foreign Function Interface )这个特性,有可能会是 Java 自诞生以来最重要的两个特性之一,它和外部内存接口一起,会极大地丰富 Java 语言的生态环境。不过,和 Java 的外部内存接口特性一样,这个特性目前依然在孵化期。
像 Java 或者 Go 这样的通用编程语言,都需要和其他的编程语言或者环境打交道,比如操作系统或者 C 语言。Java 是通过 Java 本地接口(Java Native Interface, JNI) 来实现的。
不过, JNI 的方式存在很多问题:
- 复杂:实现起来过于复杂,步骤繁琐,并且需要你掌握其他编程语言的专业知识。(具体的步骤可以参考这篇文章:Guide to JNI (Java Native Interface) )。
- 不安全:不受 JVM 的语言安全机制控制,因此,JNI 本质上是不安全的。
- 影响跨平台 :如果调用的其他编程语言不是跨平台的(比如 C 语言),那么就会影响到 Java 语言的跨平台特性。
上面的这些问题可以通过 Java 的外部函数接口 解决。Java 的外部函数接口调用 C 语言的示例如下:
import java.lang.invoke.MethodType;
import jdk.incubator.foreign.*;
public class HelloWorld {
public static void main(String[] args) throws Throwable {
try (//定义了内存资源的生命周期管理机制。
ResourceScope scope = ResourceScope.newConfinedScope()) {
//CLinker 实现了 C 语言的应用程序二进制接口(Application Binary Interface,ABI)的调用规则。
//可以用来链接 C 语言实现的外部函数
CLinker cLinker = CLinker.getInstance();
MemorySegment helloWorld =
CLinker.toCString("Hello, world!\n", scope);
MethodHandle cPrintf = cLinker.downcallHandle(
// 使用 CLinker 的函数标志符(Symbol)查询功能,查找 C 语言定义的函数 printf
CLinker.systemLookup().lookup("printf").get(),
MethodType.methodType(int.class, MemoryAddress.class),
FunctionDescriptor.of(CLinker.C_INT, CLinker.C_POINTER));
cPrintf.invoke(helloWorld.address());
}
}
}可以看到代码中不需要再编写 C 代码,也不需要编译、链接生成 C 的动态库了。
并且,大部分外部函数接口的设计则是安全的。使用外部函数接口的代码是 Java 代码,因此也受到 Java 安全机制的约束。
在外部函数接口的提案里,我们可以看到这样的描述:
JNI 机制是如此危险,以至于我们希望库在安全和不安全操作中都更喜欢纯 Java 的外部函数接口,以便我们可以在默认情况下及时全面禁用 JNI。这与使 Java 平台开箱即用、缺省安全的更广泛的 Java 路线图是一致的。
疑问 :
JEP 191: Foreign Function Interface 提案已经暂停了这个新特性的开发。另外,JNA 可以作为这个 JNI 替代。这是目前使用最广泛的 Java 本地方法调用解决方案。
解答 :
JEP 191 被更好的方案取代了:https://openjdk.java.net/jeps/412
降低维护难度
现代密码:你用的加密算法过时了吗?
对于 JDK 的开发者来说,我们要关注JDK 的密码路线图。在JDK 的密码路线图里,JDK 会声明哪些密钥算法是危险的,哪些是过期的,以及 JDK 根据密码学的进展作出的变动。
推荐使用的算法 :
- 256 位的 AES 算法
- SHA-256、SHA-512 单向散列函数
- RSASSA-PSS 签名算法
- X25519/X448 密钥交换算法
- EdDSA 签名算法
改进的废弃,怎么避免使用废弃的特性?
在 JDK 中,一个公开的接口,可能会因为多种多样的原因被废弃。比如说,这个接口的设计是危险的,或者有了更新的、更好的替代接口。不管是什么原因,废弃接口的使用者们都需要尽快迁移代码,转换到替代方案上来。
在 JDK 中,公开接口的废弃需要使用两种不同的机制,也就是“Deprecated” 注解(annotation)和“Deprecated”文档标记(JavaDoc tag)。
如果一段程序使用了废弃接口,编译的时候,就会提出警告。但是,有很多编译环境的配置,把编译警告看作是编译错误。为了解决这样的问题,JDK 还提供了“消除使用废弃接口的编译警告”的选项。也就是 SuppressWarnings 注解。
但是! SuppressWarnings** 注解会抵消 Deprecated 注解的功效,时间一长,你就忘记了还有一个废弃的接口需要被处理。**
在 JDK 9 的接口废弃机制里有了重大的改进:
- jdeprscan 这个工具可以扫描编译好的 Java 类或者包,看看有没有使用废弃的接口了。即使代码使用了
SuppressWarnings注解,jdeprscan 的结果也不受影响。 Deprecated注解增加了一个“forRemoval”的属性。如果这个属性设置为“true",那就表示这个废弃接口的删除已经提上日程了。Deprecated注解增加了一个“since”的属性。这个属性会说明这个接口是在哪一个版本废弃的。
在 Object. 类中,finalize() 方法就是在 JDK9 被废弃的, 而且 forRemoval=true:
@Deprecated(since="9", forRemoval=true)
protected void finalize() throws Throwable { }源码地址:https://github.com/openjdk/jdk/blob/master/src/java.base/share/classes/java/lang/Object.java#L576 。
模块系统:为什么 Java 需要模块化?
模块化可以帮助各级开发人员在构建、维护和演进软件系统时提高工作效率
Java 模块的使用是简单、直观的。Java 模块的使用,实现了更好的封装,也定义了模块和 Java 包之间的依赖关系。有了依赖关系,Java 语言就能够实现更快的类检索和类加载了。这样的性能提升,通过模块化就能实现,还不需要更改代码。
更新: 2021-12-31 16:39:14
原文: https://www.yuque.com/snailclimb/to3hqu/ycfiyg